リンクタグとは・・・HTMLで、<head>タグ内に記述することができ、そのページと別のページとの関係を定義することができます。
「HTML」とは、当ページのように、Webページを作成するために用いられる言語(技術)になります。
インターネット上に公開されているWebサイト(ページ)は、この「HTML」で作成されているのがほとんどです。
また、“ < ” と “ > ” で記述する「タグ」と呼ばれる特殊な記号で、記述されているのが特徴です。
※「リンクタグ」には、「a(アンカー)タグ」を用いたリンクを意味する場合もありますが、今回の記事で解説していくのは、<link>タグの事なので、注意してください。
では、本題に戻ります。
まずは、以下に「リンクタグ」の記述例を示します。
<head>
<link rel=”prev” href=”prev.html”> ←前のページ
<link rel=”next” href=”next.html”> ←次のページ
</head>
上記のように、「Head」タグの中に記述でき、意味としては
- 【一つ目】:「prev.html」は、当ページの前のページ
- 【二つ目】:「next.html」は、当ページの次のページ
と定義しています。
下図を例にしたら、意味が分かると思います。下図は、Googleの検索結果ページで、下にスクロールしたら出てきます。
次の検索結果ページを表示させたい場合は、「次へ」を押して、前のページに戻りたいときは「前へ」をクリックすると思います。

このように、そのページの「前」や「次」に、(コンテンツ内容が)紐付いている場合は、上記で記述した「リンクタグ」を用いて、定義してやります。
ですが、「リンクタグ」を設定しても、そのページをみたユーザーには、「このページの次のページは、●●●ページだ」なんて事は、全く分かりません。
下図に例を示しましょう。
下図は、上記で記述している「リンクタグ」を設定しているページですが、コンテンツ内容には全く反映されていませんよね。
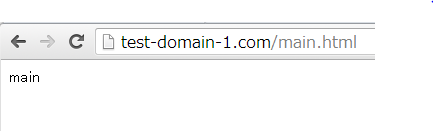
ですが、上記のソースを見てみると、ちゃんとリンクタグは設定されています(下図)
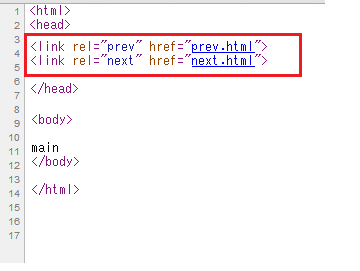
要は、ユーザーが見える部分には、「リンクタグ」の内容は全く表示されないのです。
では、何のためにこの「リンクタグ」を設定するのか・・・
今回の記事では、この「リンクタグ」の必要性と、上述以外にも「様々な利用用途」があるので、そちらを解説していきます。
以下、目次になります。
- HTMLの「リンクタグ」の必要性は、検索エンジン(クローラー)に有り
- HTMLの「リンクタグ」の様々な使い方をまとめてみた
HTMLの「リンクタグ」の必要性は、検索エンジン(クローラー)に有り

上述している通り、「リンクタグ」の内容は、ユーザーには全く関係ないと言っていいでしょう。
わざわざソースを見ないと、確認することもできません。
普通にページを閲覧しているだけでは、「リンクタグ」など意識する機会もありません。
では、なぜ「リンクタグ」は存在するのか?
それは、検索エンジン(クローラー)の存在が大きな理由です。
検索エンジンには、「クローラー」というプログラムが随時動いていて、その「クローラー」が世界中のWebページをリンクを介して、巡回しています。
そして、巡回したWebページを、検索エンジン(本体)に登録(インデックス)する。といった事を自動で「365日」おこなっています。
クローラーについて、詳しくはこちらで解説しています→【クローラーとは?「Googlebot」にクローリングさせたい場合とさせたくない場合の対処法】
この「クローラー」ですが、Webページを認識するのに「リンクタグ」の内容も参考にしているのです。
例えば、最初に記載した
<head>
<link rel=”prev” href=”prev.html”> ←前のページ
<link rel=”next” href=”next.html”> ←次のページ
</head>
であれば、クローラーは「このページの前のページは「prev.html」で、次のページは「next.html」だな」と認識しているのです。
このように、リンクタグを記述する理由は、検索エンジンに「Webページを正確に(管理者の意図通りに)、認識してもらう事」が主な理由です。
次章は、この「リンクタグ」の様々な「使い方」について、順に解説していきます。
HTMLの「リンクタグ」の様々な使い方をまとめてみた
前の章で、「リンクタグ」は、検索エンジンに「Webページを正確に(管理者の意図通りに)、認識してもらう」ために利用すると解説してきました。
その例として、「prev(前のページ)」と「next(次のページ)」を出しましたが、「リンクタグ」には、他にも様々な事を指定できます。
当章では、それらをまとめていきます。
では、順に解説していきましょう。
- 【トップページを定義する】
「記述例」
<link rel=”index” href=”https://viral-community.com/”>サイトのトップページを指定する時に使用します。上記であれば「https://viral-community.com/」がトップページになります。
- 【目次ページを定義する】
「記述例」
<link rel=”contents” href=”sitemap.html”>一連のコンテンツで、複数ページに分割されている場合、それらのページの「目次ページ」を指定するときに使用します。
「一連のコンテンツで、複数ページに分割されている」とは、下記ページのような状態を指します(ページ内容は全く関係ありません)
下にスクロールしていくと、コンテンツがページ分割していることが分かります(下図参考)

- 【検索ページを定義する】
「記述例」
<link rel=”search” href=”search.html”>例えば、「main.html」というページに上記を記述した場合、「search.html」が、「main.html」に関連するページの「検索ページ」になります。
- 【ヘルプページを定義する】
「記述例」
<link rel=”help” href=”help.html”>例えば、「main.html」というページに上記を記述した場合、「help.html」が、「main.html」に関するヘルプページになります。
- 【前のページ・次のページを指定する】
「記述例」
<link rel=”prev” href=”prev.html”>
<link rel=”next” href=”next.html”>上述している通り、一連のコンテンツでページが分割されている場合、前のページ(or次のページ)を指定するときに使用します。
また、「prev」「next」の役割はこれだけではありません。
「SEO」的な面でも、有用なメリットがあるのです。※SEOについてはこちらで解説しています→SEO対策とは
例えば、下記のように一連のコンテンツでページが分割されている場合
https://viral-community.com/contents?page=1
https://viral-community.com/contents?page=2
https://viral-community.com/contents?page=3
https://viral-community.com/contents?page=4
「prev」「next」を、各ページに指定することによって(最初のページには「next」、最後のページには「prev」のみ指定する)
「被リンク」のような検索エンジンからの評価に関連する要素を、「全体で1つ」のものとして見なしてくれます。
例えば、「page=1」に集まっている被リンクと「page=2」に集まっている被リンクは、通常「それぞれのページで別もの」として扱われますが、「prev」「next」を指定することで、全ページに集まっている被リンクを、総合し1つのものとして扱ってくれます。
これによって、同じコンテンツなのに、検索エンジンからの評価がバラバラだったものを1つに集中させる事ができます。
また、これだったら「rel=”canonical”(後述します)」と一緒では・・・?
と思うかもしれませんが、全く違います。
「rel=”canonical”」の場合、検索エンジンに登録(インデックス)されるのは「rel=”canonical”」によって指定された「1つのページのみ」です。
例えば、上記であれば「page=1」に対して「page=2~4」で「rel=”canonical”」を指定した場合、検索エンジンにインデックスされるのは、「page=1」のみになります。
ですが、「prev」「next」の場合は、全てのページ「page=1~4」が検索エンジンにインデックスされます。かつ、全ページに対しての評価は「1つに集中したもの」となります。
これが大きな違いとなります。
一点注意点としては、「一連のコンテンツを、複数のページで分割した場合のみ使用する」という事です。
あくまで、それぞれのページ内容は(関連しては、いるが)同じものではありません。「prev」「next」の場合は、検索エンジンは全ページを認識しますので、もしそれらのページが重複している場合、「重複コンテンツ」として見なし、ペナルティを受けてしまいます。
ページ内容が同じ場合は、「rel=”canonical”」を利用するようにしましょう(後述しています)
また、「prev」「next」が設定されたページ群のうち、どのページが「検索結果」に表示されるのかは、「検索クエリ」にもっとも関連したページが表示されます(通常は「1ページ目」が表示されます)
※「prev」「next」に関して、参考にさせてもらったページ:「海外SEO情報:Google、ページネーション問題を解決するrel=“next”タグとrel=“prev”タグをサポート開始」
- 【スタートページを定義する】
「記述例」
<link rel=”start” href=”start.html”>一連のコンテンツでページが分割されている場合、最初のページを指定するときに使用します。
- 【検索エンジン対策で、代替先のページを指定する】
「記述例」
<link rel=”canonical” href=”main.html”>例えば、「sub.html」というページに上記を記述した場合、検索エンジンは「sub.html」を「main.html」として認識します。
サイトに、オリジナルページと、それに対する「複数のコピーページ」があった場合、それらのコピーページを「1つのオリジナルページ」として、検索エンジンに認識させたい時に利用します。
例えば、コンテンツが一緒の「モバイル版」や、「WWW」のあり・なし。であったり、「index.html」のあり・なし等は、検索エンジンからみたら、同一コンテンツなのに、複数のページがある(URLが違うので)、と認識されてしまいます。
これは、SEO的には非常に不利な状態となります。
なぜなら、検索エンジンからの評価が、各ページ毎に分散されてしまいます。
また、もっとヒドイと「重複コンテンツ」として見なされ、ペナルティを受けてしまう場合もあります。なので、予め「このページは、「mainページ」と重複しているコンテンツなので、「mainページ」として扱ってください」としておくための「リンクタグ」になります。
このように「検索エンジン最適化」のために利用されるのが、「rel=”canonical”」になります(検索エンジン最適化については、こちらで解説しています→【検索エンジン最適化とは?検索エンジン対策ですべき事が「過去と現在」で全く違っている件について】)
もし、上記のように「重複コンテンツ」がある場合は、必ず指定しておきましょう。
- 【参照する「CSSファイル」を指定する】
「記述例」
<link rel=”stylesheet” href=”test.css” type=”text/css”>例えば、「main.html」というページに上記を記述した場合、「main.html」は、「test.css」を「CSSファイル」として読み込みます。
以上、「リンクタグ」の様々な使い方でした。