
「robots.txt」とは・・・Webサイトのディレクトリorファイルへの「クローラー」のアクセスを制御するために使われるテキストファイルです。
例えば、「SEO」というディレクトリにあるファイルには、アクセスさせないとか、「seo.html」というファイルにはアクセスさせない。といった設定ができます。
※「robots.txt」の解説に入るまえに、まずは「クローラー」の仕組みについて、理解しておかなければなりません。クローラーの仕組みについてはこちらで解説しています→クローラーとは?「Googlebot」にクローリングさせたい場合とさせたくない場合の対処法
今回の記事では、この「robots.txt」の具体的な利用用途の解説と、「robots.txt」の書き方(作成手順)について解説していきます。
以下、目次になります。
- 「robots.txt」の利用用途を理解しておく
- 「robots.txt」の書き方(作成手順)
「robots.txt」の利用用途を理解しておく
上述している通り「robots.txt」は、Webサイトのディレクトリorファイルへの「クローラー」のアクセスを制御するために利用されます。
「アクセスを制御」とありますが、実際は、主に検索エンジンが「自分のサイト(ページ)」にアクセスしないように設定する事がほとんどです(検索エンジンは、デフォルトでアクセス許可となっているので)
要は、検索結果に「自分のサイト(ページ)」を表示したくない(インデックスしたくない)時に、利用されるのです。
その理由としては、以下が当てはまるかと思います。
- 限られた人にしか、サイト(ページ)を公開したくない
- なにかしらの理由で、同じコンテンツが複数ある場合に、「検索エンジン」に複数コンテンツ扱いされたくないから(同じコンテンツが複数あって、検索エンジンから「コピーコンテンツ」と判断されたら、どれか一つが検索結果に表示される事になります。なので、メインのページをちゃんと検索結果に表示させたい場合などが当てはまります)
またSEO的にいえば、下記のようなページは「クロール」させない方が良いでしょう(「クロール限度数」を考慮して、無駄にクローリング数を消費しないようにするため)
- 検索エンジンにインデックスさせなくても良いページ
- ユーザー(訪問者)にとって価値のないページ
- サイトに入れている広告の「リンク先ページ」
以上です。
このように、検索結果に「自分のサイト(ページ)」を表示したくない時に、「robots.txt」は利用されます。
次は、「robots.txt」の作成手順について解説していきます。
「robots.txt」の書き方(作成手順)
「robots.txt」は、エディタ(メモ帳等)で作成できるシンプルな「テキストファイル」です。
以下に、ファイル内容の例を示します。
Disallow: /seo/seo.html
上記は、どうゆう意味か・・・Google検索エンジンのクローラー(Googlebot)が、「/seo/seo.html」ファイルにアクセスできないように設定しています。
非常にシンプルですよね。構成項目としては下記二点になります。
- 【アクセスを制限したいクローラー】:User-agent: Googlebot
- 【アクセス制限対象のファイル(又はディレクトリ)】:Disallow: /seo/seo.html
これだけです。
以下、補足情報になります。
- 【クローラーの指定】:Googleだけじゃなく、YahooやMSN等、すべてのクローラーを指定する場合の表記(以下)
User-Agent:*
- 【ファイル(orディレクトリ)の指定】:サイト全体のファイルや、指定のディレクトリ内のファイルを指定する場合の表記(以下)
サイト全体: Disallow: /
指定ディレクトリ全体: Disallow: /junk-directory/ - 【アクセス許可設定】:あまり利用されませんが、アクセス制限だけじゃなく、アクセス許可も明示的に指定できます(デフォルト設定は、アクセス許可されている)
Allow: /seo/seo.html
「robots.txt」ができあがったら、そのファイルは、「サイトのルートドメイン(ルートディレクトリ)」に置いてください。
例えば、当サイトであれば、ドメインが「viral-community.com」なので、「viral-community.com/robots.txt」に設置してください。
設置方法については、「FFFTP」などのFTPツールを利用するか、レンタルサーバーをご利用であれば、レンタルサーバーの提供している「FTPツール」を利用して、ファイルをアップ(設置)すればよいでしょう。
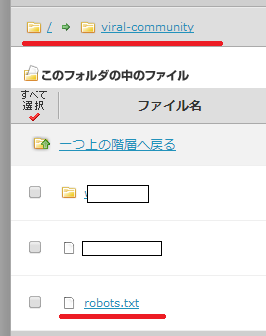
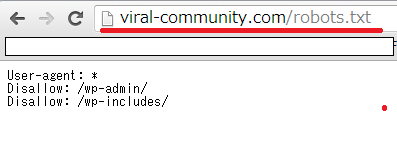
ちゃんと設置できたかの確認は、当サイトであれば「https://viral-community.com/robots.txt」をブラウザ表示して、下図のようにちゃんと表示されたら「OK」です。
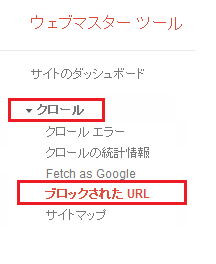
また、Googleウェブマスターツールでも、正常に「robots.txt」が機能しているかの確認ができます(事前に、Googleウェブマスターツールに、自分のWebサイトを登録しておく必要があります。登録手順に関してはこちらで解説しています→【Googleウェブマスターツール(WebMasterTool)へのサイト登録と基本的な使い方】)
Googleウェブマスターツールの管理画面を開いたら、左のメニュー「クロール」から「ブロックされたURL」を選択してください(下図参考)
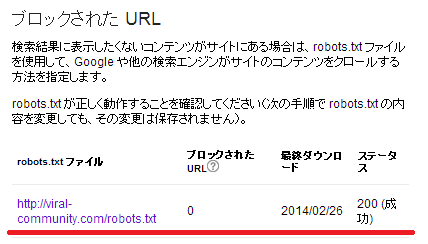
すると、サーバーにアップしている「Robots.txt」ファイルが、ちゃんとGoogleに認識されているかが確認できます。
ステータスが「200(成功)」となっていたら、OKです(下図参考)
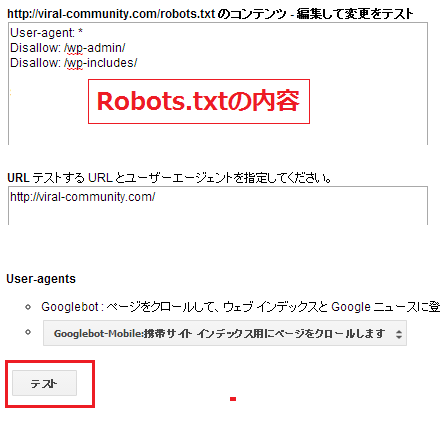
さらに、下にスクロールしていくと「Robots.txt」でちゃんとアクセス制限されているかの「テスト」もおこなうことができます(下図参考)
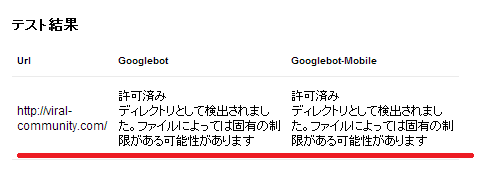
テスト結果にて、ちゃんと指定したファイル(又はディレクトリ)がアクセス制限されているのかチェックしておきましょう。
以上です。
まとめ
今回の記事では、「robots.txt」とは何なのかの解説と、「robots.txt」の書き方(作成手順)について解説してきました。
今回は、「robots.txt」によって「クローラー」からのアクセス制限をする手順を解説してきましたが、「クローラー」からのアクセス制限をする方法はもう一つあります。
それは、「METAタグ」での指定です。
「METAタグ」とは、HTMLファイルに表記できるタグの一つで、Webページに関する情報を定義することができます。
この「METAタグ」ですが、検索エンジンのクローラーにクローリングさせないように設定することもできるのです。
なので、クローリングさせたくないファイル(HTML)に、「METAタグ」を設定する事で、そのファイルはクローリングされません。
詳しい手順に関しては、こちらで解説しています→【<meta name=”robots” content=”noindex”> で、クローラーを拒否してみた】