
「クローラー」を理解するには、まず「検索エンジン」の仕組みを知っておかなければなりません。

上図のように、検索エンジンが検索結果として「様々なWebページ」を表示する際、内部的には、下記のような流れになっています。
- ユーザーが「SEO(例)」というキーワードで検索します
- 検索キーワードを受け取った「検索エンジン」は、検索エンジン側で保持しているデータベースを参照しにいって、「検索キーワード」に紐づくWebページ群を取得します
- 取得したWebページ群を、検索結果として表示します
以上が、内部的な流れになります。
上記で「検索エンジン側で保持しているデータベース」と記載しましたが、このデータベースに「世界じゅうのありとあらゆるWebページの情報」が格納されています。
「クローラー」の話しに戻りますが、クローラーの役目は、このデータベースに「存在していないWebサイトの情報」を格納したり、Webサイトの内容が更新されていたら、その更新内容をデータベースに反映させていくのが、役目になります。
「クローラー」じたいは、プログラムになっていて、Webサイト(ページ)間のリンクを辿っていき、辿りついたページ情報を自動的に取得していきます。
そして、取得したページ情報を「データベース」に格納していくのです。
呼び名は様々で、「ボット」「ロボット」「スパイダー」とも呼ばれています。
今回の記事では、Googleのクローラーである「Googlebot」についての解説と、「Googlebot」にクローリングさせたい場合とさせたくない場合の対処法について。
また、クローリング頻度を確認する手順についても解説していきます。
以下、目次になります。
- Googleのクローラー「Googlebot」について
- 「Googlebot」にクローリングさせたい場合
- 「Googlebot」にクローリングさせたくない場合
- 「Googlebot」のクローリング頻度を確認する手順
Googleのクローラー「Googlebot」について

検索エンジンで最も一般的な「Google」のクローラーは「Googlebot」と呼ばれています。
仕組みや役割は、上述している内容と全く一緒で、Googleでは、大規模なコンピュータ群を使用して、Web上の数十億のページを取得(クローリング)しています。
また、Google独自のアルゴリズムによって、下記が決定されます。
- クローリングするサイト
- クローリングの頻度
- 各サイトから取得するページ数
SEO的にいえば、クローリングの頻度が多い方が、Webサイトや各ページの更新情報をGoogle側に連携する回数が増えるので、それだけ有利になります。
全くクローリングされない場合は、SEO以前の問題で、そもそもGoogleの検索結果として表示される対象に入っていない(インデックスされていない)ということになります。
なので、次章では、「Googlebot」にクローリングさせたい場合の対策を解説していきます。
「Googlebot」にクローリングさせたい場合

上述している通り、クローリング頻度が多い方が、Webサイトや各ページの更新情報をGoogle側に連携する回数が増えるので、それだけSEO的に有利になります。
そこで下記に、より「Googlebot」にクローリングさせる対策を4つにまとめました。
- 【サイトの更新頻度を高くする】:Googleは、更新頻度が高いWebサイトには頻繁にクロールする傾向があるようです。
Googleは、どれ位の頻度でWebサイトが更新されているのかをチェックしていて、1週間に1回しか更新されていないものより、毎日更新しているものを優先します。
ただ、注意しないといけないのが、いくら更新頻度が高くても「低品質なコンテンツ」のものは、インデックスされないので、注意してください。
- 【XMLサイトマップの作成と、Googleへの連携】
「xmlサイトマップ」とは・・・Webサイトやブログ内にあるページを、いち早く検索エンジン(google等)に登録するためのものです。
この「サイトマップ」を利用することで、検索エンジンにページの存在を知らせ、クローラーの巡回を促すことができます。
サイトマップの作成手順と、Googleへの連携手順についてはこちら→【サイトマップとは?Google xml sitemapsプラグインでWordpressブログのサイトマップを作成してみる】 - 【「Fetch as Google」を利用して、Googleへのクローリング要求をする】:「Fetch as Google」とは、「Googleウェブマスターツール」の機能で、Googleに速やかなクローリングを要求することができます(通常は1日以内にクロールされます)
「Fetch as Google」の利用手順に関しては、こちらで解説しています→「Fetch as Google」で、Googleにインデックスのお願いをする手順をまとめてみた
- 【外部リンク・内部リンクを増やす】:上述しているとおり、クローラーはWebサイトの「リンク」を辿ってやってくるので、外部サイトからのリンクや内部リンクが増えれば増えるほど、クローラーがやってくる頻度は増えていきます
以上が、「Googlebot」にクローリングさせる対策になります。
次は、逆に「Googlebot」にクローリングさせたくない場合の対策について解説していきます。
「Googlebot」にクローリングさせたくない場合

まず、「Googlebot」にクローリングさせたくない場合とは、どういった理由からなのか、、、
大きく2つに分けてみました(下記)
- 限られた人にしか、公開したくないサイト(ページ)だから
- なにかしらの理由で、同じコンテンツが複数ある場合に、「検索エンジン」に複数コンテンツ扱いされたくないから(同じコンテンツが複数あって、検索エンジンから「コピーコンテンツ」と判断されたら、どれか一つが検索結果に表示される事になります。なので、メインのページをちゃんと検索結果に表示させたい場合などが当てはまります)
以上、2つが主な理由でしょう。
では、本題の「Googlebot」にクローリングさせないようにする対策ですが、以下二点になります。
- 【METAタグを設定する】
「METAタグ」とは、HTMLファイルに表記できるタグの一つで、Webページに関する情報を定義することができます。
Webページの情報とは、下記のような項目が挙げられます。
・ページ内容の要約(説明文):例・・・”このページは「SEO」について記載されたページです”
・ページ内容の要約(キーワード):例・・・”SEO”
・ページの著者:例・・・”佐藤太郎”
・ページの著作権者:例・・・”佐藤太郎”など、まだまだ様々な項目がありますが、このようにWebページに関する情報を定義できるのが「METAタグ」になります。
この「META」タグですが、検索エンジンのクローラーにクローリングさせないように設定することもできます。
設定手順に関してはこちらで解説しています→【<meta name=”robots” content=”noindex”> で、クローラーを拒否してみた】
- 【robots.txtを設定する】
「robots.txt」は、「自分のサイトのファイルとディレクトリ」へのクローリングを制御するために使われます。
例えば、「SEO」というディレクトリにあるファイルには、クローリングさせないとか、「seo.html」というファイルにはクローリングさせない。といった設定ができます。
「robots.txt」の設定手順に関してはこちらで解説しています→【robots.txtとは?「robots.txt」の書き方をまとめてみた】
以上が、「Googlebot」にクローリングさせないようにする対策になります。
「Googlebot」のクローリング頻度を確認する手順
当章では、自分のサイトに「Googlebot」が1日にどのくらいクローリングしてきているのかを確認する手順を解説していきます。
確認するには、「Googleウェブマスターツール」を利用します(事前に、Googleウェブマスターツールに確認したいサイトを登録しておく必要があります。登録手順に関してはこちら→【Google対策に必須!ウェブマスターツール(WebMasterTool)へのサイト登録と基本的な使い方】)
では、順に手順を解説していきます。
まず、「Googleウェブマスターツール」を開いて、確認したいサイトを選択します(下図参考)

次に、左のメニュー「クロール」から「クロールの統計情報」をクリックしてください(下図参考)
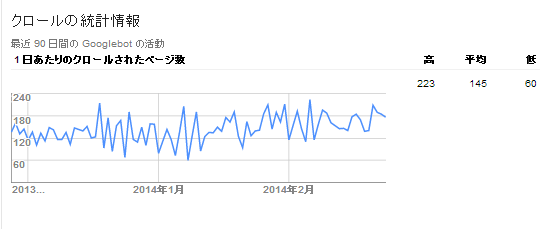
すると、下図のように「1日あたりのクロールされたページ数」が、90日間分グラフ表示されています。
こちらで、自分のサイトがどのくらいクローリングされているかを確認することができます。
以上です。
まとめ
今回の記事では、クローラーについての解説と、「Googlebot」にクローリングさせたい場合とさせたくない場合の対処法について。また、クローリング頻度を確認する手順についても解説してきました。
上述している通り、クロールの頻度は「SEO」と相関関係があります。
クロールされる頻度が多いほど、SEO的に検索エンジンからの評価が高くなります。
以下に、その証拠となる内容が載っていますので、参考までに確認しておく事をオススメいたします。
また、クローラーが1回の訪問時にクローリングできる回数(クロール限度数)は、サイトによって決められています(サイトのオーソリティが高ければ、クロール限度数は増える)
なのでSEO的に、以下に示すページはクローリングさせないように設定しておきましょう。
- 検索エンジンにインデックスさせなくても良いページ
- 広告のリンク先ページ(さらに、広告ページに対するリンクには「rel=”nofollow”」をつけておくべき)
- ユーザー(訪問者)にとって、価値のないページ